My 70TB solo Chia farm reminded about itself after three months by producing 2 blocks, with about two weeks inbetween. This was an impulse for me to update it with things that were introduced during this time. Biggest change was pooling so I have created NFT, joined space.pool and started plotting. I was curious how it is to work with bigger files so I have decided to add k33 and k34 plots to my farm. K35 are IMHO too uncomfortable at the moment and there’s higher chance that with time e.g. bad block/sector will appear and it will be impossible to move such a big file to other device. I ended with mix of 103GB, 209GB and 430GB files and since these filesizes don’t increase geometrically I thought that it would be wise to fill space as efficiently as I can.
After few weeks I have already plotted big enough sample of different k-sizes so last thing left was finding biggest files from each category. I have a single harvester that has all the drives pooled with mergerfs so the fastest way was to list all files sorting them by size with ls -lS --block-size=M /mnt/chia/farm and pick largest ones (rounding them a bit) manually. My google-fu failed me this time and not being able to find efficient and satysfying solution online I came up with this script:
from collections import Counter
#disk_space = 4658 # G
#plot_sizes = {'k34': 430, 'k33': 209, 'k32': 102}
disk_space = 4767650 # M
plot_sizes = {'k34': 440220, 'k33': 213900, 'k32': 103900}
res = {}
def get_combinations(total_size, history, last_size):
for plot_size, file_size in plot_sizes.items():
if file_size <= last_size:
if total_size + file_size <= disk_space:
get_combinations(total_size + file_size, history + [plot_size], file_size)
else:
free_space = disk_space - total_size
if free_space < min(plot_sizes.values()):
if str(free_space) not in res:
res[str(free_space)] = []
res[str(free_space)].append(sorted(Counter(history).items(),reverse = True))
break
get_combinations(0, [], plot_sizes['k34'])
sortedKeys = list(res.keys())
sortedKeys.sort(key=int)
for key in sortedKeys:
print(key, res[key])And here is the output:
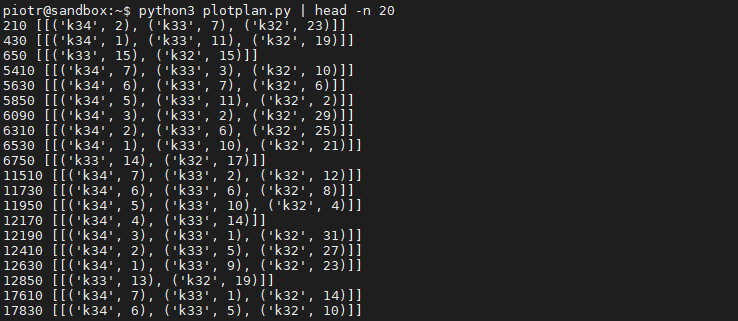
The outcome was that instead of losing 90GB from each 5TB disk, like it was with OG non-NFT plots, I’m leaving max few gigs free.